
新建爬虫类
把一些基础的信息初始化,方便在之后的方法中增加、删除、修改、使用这些数据。这些信息,在搜索课程和选课时都会用到。
1 | class LessonSpider: |
获取选课信息
Chrome F12 进行逆向工程(俗称抓包),查看正常浏览(网上选课——公选课)时,会发出哪些数据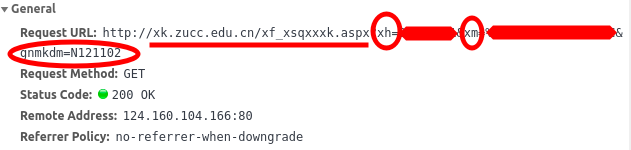
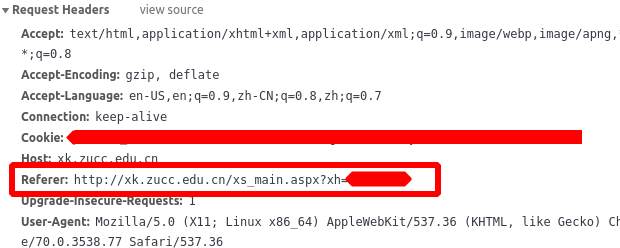
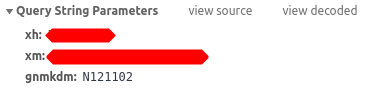
- 请求的URL就是网址+‘xf_xsqxxxk.aspx’
- 构造要发送的数据包中有学号,gb2312编码的姓名和gnmkdm
- headers中需要增加Referer,就是当前页面的地址
1 | def hello_zf(self): |
抓取已经选择的课程信息
用lxml解析get到的公选课课程页面,通过xpath定位到已经选择的课程列表。另外计数已经选择的课程,用于之后判断选课是否成功
1 | def already(selector): |
新建课程类
通过新建一个课程类,来方便管理获取到的课程信息
其中code被用作公选课选课时的提交代码,构造数据包时要用到
1 | class Lesson: |
搜索课程
发送查询请求
抓取了搜索课程的包,忽略值为空的键
- __VIEWSTATE: 每提交一次请求,会get到一个新的值,并且在下一次请求中必须使用最新的值,定义一个函数用以更新这个值
1 | def set_view_state(self, selector): |
ddl_ywyl: ‘%D3%D0’ 中文“有”的gb2312编码,表示查询还有余量的公选课;’%CE%DE’表示“无”;为空表示查询所有
ddl_xqbs: 1 相传这个是校区代码,每个学校都不一样。这里就保持1就OK
TextBox1: 要查找的课程名的GB2312编码
dpkcmcGrid:txtChoosePage: 1 表示选择的页数,默认1
dpkcmcGrid:txtPageSize: 200 为一页显示多少数据,经过测试,服务器最多响应200条,公选课也就一百多门,这里写200也就保证了上面那个值写1也能抓到所有课程。如果有一天,超过200门公选课了,就需要修改代码,循环抓取每一页的课程了
Button2: 确定的GB2312编码,相当于查询时的那个确定按钮
1 | def search_lessons(self, lesson_name=""): |
获取课程信息
lxml解析查询得到的页面,xpath定位所有课程信息的位置,转换为Lesson的对象存入元组中方便选课
1 | def get_lessons(selector): |
进行公选课选课
这里post的数据包比起基础包要多两个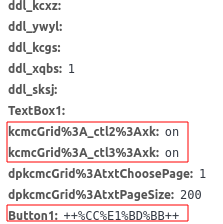
- Button1: ‘ 提交 ‘的GB2312码(提交前后分别有两个空格)
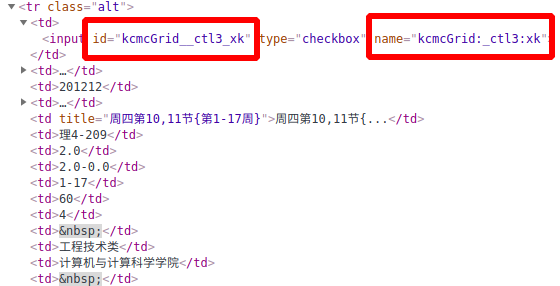
- 之前说的Lesson类中有一个code,就是这里需要提交的数据里面的键,对应的值是‘on’,相当于是勾选了每门课程前面的那个checkbo类型的input。审查元素的时候,可以在每门课程的input标签中name属性和id属性中获得
1 | def select_lesson(self, lesson_list): |
这里还用到一个显示错误的函数,原理也是解析页面后查看html>head>script的值,用正则表达式查找是否有alert的弹窗,显示alert中的内容
1 | def show_error(selector): |
完整代码
Lesson.py
1 | import re |
PublicCourseSpider.py
1 | import copy |